1.0.0-m1版本中的监控
微服务框架从0.5.0版本开始支持监控功能Metrics,1.0.0-m1版本正式发布,请通过查看用户手册和Release Note获取更多信息,我们也会继续追加新特性新功能,欢迎订阅ServiceComb邮件列表(dev-subscribe@servicecomb.apache.org)参与讨论。
背景
将系统微服务化是技术潮流和趋势,但是它解决了很多问题的同时也带来了新的问题。
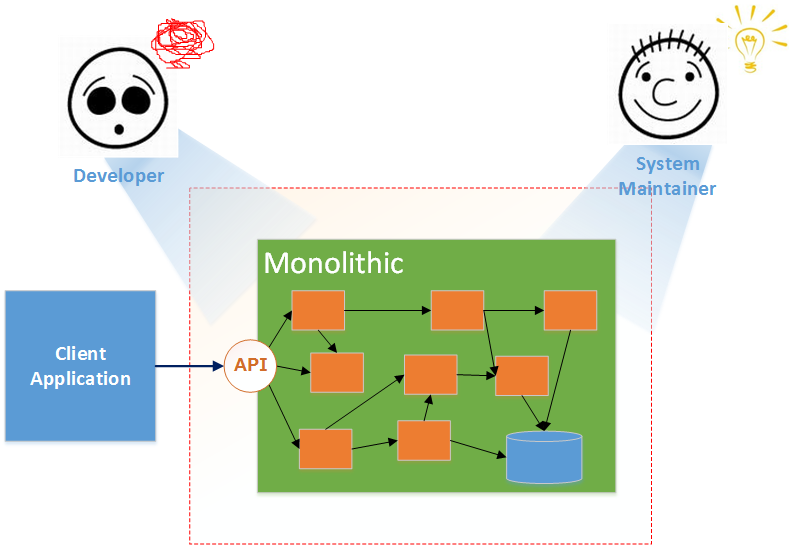
这是传统单体系统架构图,对运维人员友好,但是对开发人员不友好,系统维护升级困难。
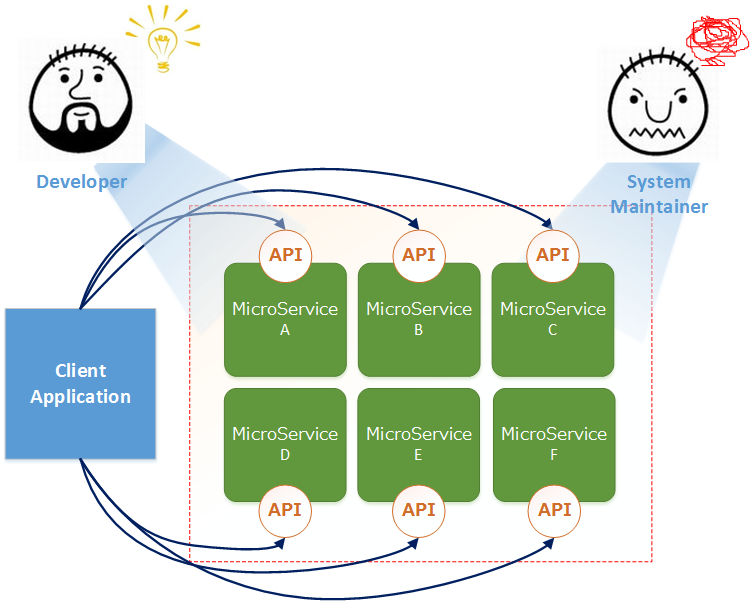
这是微服务化后的系统架构图,经过功能切分,开发人员获得了架构独立、快速迭代等诸多微服务带来的好处,但是运维人员却需要维护海量的微服务实例,所以如果不进行性能监控,当系统出现故障或用户体验下降时,就无法快速定位问题,也无法制定策略(例如弹性伸缩)来预防。
1.0.00-m1版本原理
在0.5.0版本的实现介绍0.5.0版本中的监控中,存在一些问题:
- metrics在foundation-metrics模块中实现,并且包含了一些具体的定制代码;
- 使用ThreadLocal变量收集和汇总数据,虽然性能很高,但是存在内存泄漏的风险;
- Metrics的输出为固定的文本,而不是独立的数值,数据使用起来很不方便;
- 没有提供通用数据发布接口,难以和更多的第三方监控系统做集成;
- 由于foundation-metrics模块过于底层,用户无法以可选的方式决定是否启用;
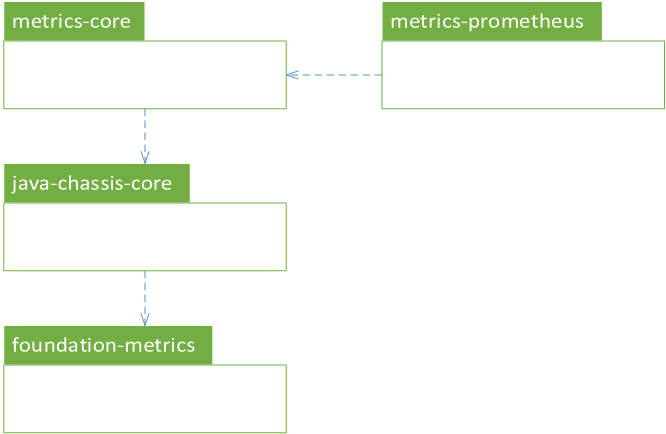
因此,从0.5.0版本升级到1.0.0-m1版本,我们进行了一次全面的重构,重构后的Metrics将分为如下两个个模块
| Module名 | 描述 |
|---|---|
| foundation-metrics | Metrics机制层模块,提供Metrics基础能力 |
| metrics-core | Metrics核心模块,引入后即启用Metrics数据收集功能 |
| metrics-integration | 包含Metrics与其它三方系统集成 |
它们的依赖关系如下图所示:
数据采集不再依赖Hystrix(handler-bizkeeper),使用事件埋点收集与调用相关的所有数据
1.0.0-m1版本不再从Hystrix获取调用的TPS和Latency,避免了不配置Java Chassis Bizkeeper Handler就不会输出这两项数据的问题;使用foundation-common中的EventBus作为事件总线,EventBus初始化的时候会通过SPI(Service Provider Interface)的机制将所有的EventListener注册进来,已实现的EventListener包括:
| 事件监听处理类名 | 功能 |
|---|---|
| InvocationStartedEventListener | 处理Consumer调用或Producer接收开始时触发的InvocationStartedEvent |
| InvocationStartExecutionEventListener | 处理Producer从队列中取出调用开始处理时触发的InvocationStartExecutionEvent |
| InvocationFinishedEventListener | 处理Consumer调用返回或Producer处理完毕触发的InvocationFinishedEvent |
特别说明,Java Chassis的Reactor框架基于Vertx,在同步调用模式下,微服务Producer端收到Invocation后,并不会马上同步处理请求,而是将它放入一个处理队列中,Invocation在队列中的时间称为LifeTimeInQueue,队列的长度称为waitInQueue,这是衡量微服务压力的两个重要指标,可以参考操作系统磁盘读写队列的概念;Consumer端并不会有队列,因此永远不会触发InvocationStartExecutionEvent。
事件触发的代码分布在Java Chassis的RestInvocation、HighwayServerInvoke和InvokerUtils中,如果微服务没有启用Metrics,EventBus中就不会注册Metrics事件监听处理器,因此对性能的影响微乎其微。
使用Netflix Servo作为Metric的计数器
Netflix Servo具有性能极高的计数器(Monitor),我们使用了五种:
| Monitor名 | 描述 |
|---|---|
| BasicCounter | 基本累加计数器(永续累加) |
| StepCounter | 周期累加计数器(以前曾经称为ResettableCounter) |
| BasicTimer | 时间计数器 |
| BasicGauge | 基本计量器 |
| MaxGauge | 周期最大值计数器 |
依赖的Servo版本为0.10.1
周期设置
Metrics有很多种分类方式,在技术实现上我们偏向以取值方式区分为两种:
- 直接取值 任何时候都能够立刻获取到最新值,例如资源使用率,包括CPU使用率,线程数,Heap使用数据等等,还有调用累加次数,当前队列长度等等。
- 统计取值
经过一个特定的时间周期才能够统计出值,这个时间间隔我们可以称为窗口周期(Window Time)或统计周期,例如:
a) 多值取其一的,比如Max、Min、Median(中位值);
b) 与时间相关的,比如TPS(transaction per second);
c) 与个数相关的,比如累加平均值、方差等等;
获取此类Metrics的值,返回的是上一个周期的统计结果,具有一定的延后性。在Servo中,这个时间被称为“Polling Intervals”。
从1.0.0-m1开始,可以通过microservice.yaml中的servicecomb.metrics.window_time配置设置周期,效果与servo.pollers一致。
提示:Servo已经被Netflix标记为DEPRECATED,我们将在1.0.0-m2中使用Netflix spectator替换,将不需要设置周期
Metrics数据ID格式
Java Chassis Metrics内置两种类型的Metric输出:
JVM信息
输出ID格式为:jvm(statistic=gauge,name={name}) name包括:
| name | 描述 |
|---|---|
| cpuLoad | CPU使用率 |
| cpuRunningThreads | 线程数 |
| heapInit,heapMax,heapCommit,heapUsed | 内存heap使用情况 |
| nonHeapInit,nonHeapMax,nonHeapCommit,nonHeapUsed | 内存nonHeap使用情况 |
Invocation信息
输出ID格式为:servicecomb.invocation(operation={operationName},role={role},stage={stage},statistic={statistic},status={status},unit={unit}) 标签含义及值如下:
| Tag名 | 描述 | 值 |
|---|---|---|
| operationName | Operation全名 | MicroserviceQualifiedName |
| role | Consumer端统计还是Producer端统计 | consume,producer |
| stage | 统计的阶段 | queue(在队列中,仅producer),execution(执行阶段,仅producer),total(整体) |
| statistic | 统计项 | tps,count(总调用次数),max,waitInQueue(在队列中等待数,仅producer),latency |
| status | 调用结果状态值 | 200, 404等等 |
| unit | 如果是时延统计,单位 | MILLISECONDS,SECONDS等等 |
如何配置
全局配置
请在microservice.yaml中添加如下配置项:
APPLICATION_ID: demo
service_description:
name: demoService
version: 0.0.1
servicecomb:
metrics:
#时间窗间隔,单位毫秒,默认为5000(5秒)
window_time: 5000
为了降低Metrics理解和使用难度,我们暂时不支持多周期
依赖配置
只需要添加metrics-core依赖即可:
<dependency>
<groupId>org.apache.servicecomb</groupId>
<artifactId>metrics-core</artifactId>
<version>1.0.0-m1</version>
</dependency>
如何获取数据
配置好Metrics后,你可以通过如下两种方式获取Metrics数据:
通过发布接口获取
当微服务启动后,metrics-core会自动以Springmvc的方式发布服务:
@RestSchema(schemaId = "metricsEndpoint")
@RequestMapping(path = "/metrics")
public class MetricsPublisher {
@ApiResponses({
@ApiResponse(code = 400, response = String.class, message = "illegal request content"),
})
@RequestMapping(path = "/", method = RequestMethod.GET)
@CrossOrigin
public Map<String, Double> measure() {
return MonitorManager.getInstance().measure();
}
}
因此,如果你在microservice.yaml中配置了rest provider,例如:
servicecomb:
service:
registry:
address: http://127.0.0.1:30100
rest:
address: 0.0.0.0:8080
你就可以通过http://localhost:8080/metrics 直接获取到数据,打开浏览器输入此URL就可以看到返回结果。
直接获取
从上面的代码可以看到,数据提供的入口是org.apache.servicecomb.metrics.core.MonitorManager,因此如果你希望自己开发数据发布程序,只需要获取它即可。
MonitorManager manager = MonitorManager.getInstance();
Map<String, Double> metrics = manager.measure();
提示:Servo已经被Netflix标记为DEPRECATED,我们将在1.0.0-m2中使用Netflix spectator替换,获取数据的接口会有调整
如何使用数据
Metrics数据将以Map<String, Double>的形式输出,为了能够方便用户获取指定Metric的值,提供了org.apache.servicecomb.foundation.metrics.publish.MetricsLoader工具类:
//模拟MonitorManager.getInstance().measure()获取所有的Metrics值
Map<String, Double> metrics = new HashMap<>();
metrics.put("X(K1=1,K2=2,K3=3)", 100.0);
metrics.put("X(K1=1,K2=20,K3=30)", 200.0);
metrics.put("X(K1=2,K2=200,K3=300)", 300.0);
metrics.put("X(K1=2,K2=2000,K3=3000)", 400.0);
metrics.put("Y(K1=1,K2=2,K3=3)", 500.0);
metrics.put("Y(K1=10,K2=20,K3=30)", 600.0);
metrics.put("Y(K1=100,K2=200,K3=300)", 700.0);
metrics.put("Y(K1=1000,K2=2000,K3=3000)", 800.0);
//创建一个MetricsLoader加载所有的Metrics值
MetricsLoader loader = new MetricsLoader(metrics);
//获取name为X的所有Metrics并且按K1,K2两个Tag层次分组
MetricNode node = loader.getMetricTree("X","K1","K2");
//获取K1=1且K2=20的所有Metrics,因为node是按K1和K2的层次分组的
node.getChildrenNode("1").getChildrenNode("20").getMetrics();
//从层次结构中通过Tag匹配获取Metric的值
node.getChildrenNode("1").getChildrenNode("20").getFirstMatchMetricValue("K3","30");
demo/perf/PerfMetricsFilePublisher.java提供了MetricsLoader更详细的使用示例
如何扩展
Java Chassis Metrics支持自定义Metrics扩展,MonitorManager包含一组获取各类Monitor的方法:
| 方法名 | 描述 |
|---|---|
| getCounter | 获取一个计数器类的Monitor |
| getMaxGauge | 获取一个最大值统计Monitor |
| getGauge | 获取基本计量Monitor |
| getTimer | 获取一个时间计数器类的Monitor |
以处理订单这个场景为例:
public class OrderController {
private final Counter orderCount;
private final Counter orderTps;
private final Timer averageLatency;
private final MaxGauge maxLatency;
OrderController() {
MonitorManager manager = MonitorManager.getInstance();
//"商品名","levis jeans"与"型号","512" 是两个自定义Tag的name和value,支持定义多Tag
this.orderCount = manager.getCounter("订单数量", "商品名", "levis jeans", "型号", "512");
this.orderTps = manager.getCounter(StepCounter::new, "生成订单", "统计项", "事务每秒");
this.averageLatency = manager.getTimer("生成订单", "统计项", "平均生成时间", "单位", "MILLISECONDS");
this.maxLatency = manager.getMaxGauge("生成订单", "统计项", "最大生成时间", "单位", "MILLISECONDS");
}
public void makeOrder() {
long startTime = System.nanoTime();
//处理订单逻辑
//...
//处理完毕
long totalTime = System.nanoTime() - startTime;
//增加订单数量
this.orderCount.increment();
//更新Tps
this.orderTps.increment();
//记录订单生成处理时间
this.averageLatency.record(totalTime, TimeUnit.NANOSECONDS);
//记录最大订单生成时间,因为惯用毫秒作为最终输出,因此我们转换一下单位
this.maxLatency.update(TimeUnit.NANOSECONDS.toMillis(totalTime));
}
}
注意事项:
1.通过MonitorManager获取Monitor传递name和tag数组,最终输出的ID是它们连接后的字符串,所以请保持唯一性,上面的例子输出的Metrics为:
Map<String,Double> metrics = MonitorManager.getInstance().measure();
//metrics的keySet()将包含:
// 订单数量(商品名=levis jeans,型号=512)
// 生成订单(统计项=事务每秒)
// 生成订单(统计项=平均生成时间,单位=MILLISECONDS)
// 生成订单(统计项=最大生成时间,单位=MILLISECONDS)
2.MonitorManager获取Monitor的方法均为获取或创建,因此多次传递相同的name和tag数组返回的是同一个计数器:
Counter counter1 = MonitorManager.getInstance().getCounter("订单数量", "商品名", "levis jeans", "型号", "512");
Counter counter2 = MonitorManager.getInstance().getCounter("订单数量", "商品名", "levis jeans", "型号", "512");
counter1.increment();
counter2.increment();
Assert.assertEquals(2,counter1.getValue());
Assert.assertEquals(2,counter2.getValue());
Assert.assertEquals(2.0,MonitorManager.getInstance().measure().get("订单数量(商品名=levis jeans,型号=512)"),0);
获取Monitor的方法性能较低,请在初始化阶段一次获取所需的Monitor,然后将它们缓存起来,请参照前面OrderController的做法。
提示:Servo已经被Netflix标记为DEPRECATED,我们将在1.0.0-m2中使用Netflix spectator替换,扩展自定义Metrics的方式会有调整
参考示例
我们已经开发完成了两个使用场景可以作为参考:
- demo/perf:在Console里打印Metrics;
- metrics-prometheus:将Metrics发布为prometheus Producer。